An Introduction to Apache Hadoop: What Is It and How Can It Help Your Business?

What is Apache Hadoop?
Apache Hadoop is an open-source software framework that enables users to store, process, and analyze large datasets distributed across multiple computers. It is one of the most popular Big Data technologies and is used by many companies to power their data analytics.
Hadoop was developed by the Apache Software Foundation and is designed to be highly scalable, reliable, and fault-tolerant. With its powerful capabilities, Hadoop is able to handle massive amounts of data, making it ideal for businesses that need to analyze huge datasets.
Apache Hadoop Components
Although the architecture of Apache Hadoop can be quite complex, it mainly consists of two main components:
- Hadoop Distributed File System (HDFS)
- MapReduce Programming Framework
The HDFS stores data in a distributed system across multiple nodes. Whereas the MapReduce framework is for processing and analyzing the data. We’ve provided below an overview of each with diagrams of their functionality.
1. Hadoop Distributed File System (HDFS)
Hadoop Distributed File System (HDFS) is a distributed file system for storing data reliably on commodity hardware. It is a core component of the Apache Hadoop platform and provides high-performance access to data across highly scalable clusters of commodity servers. The system is fault-tolerant, meaning that data stored in HDFS is not lost even if individual nodes fail.
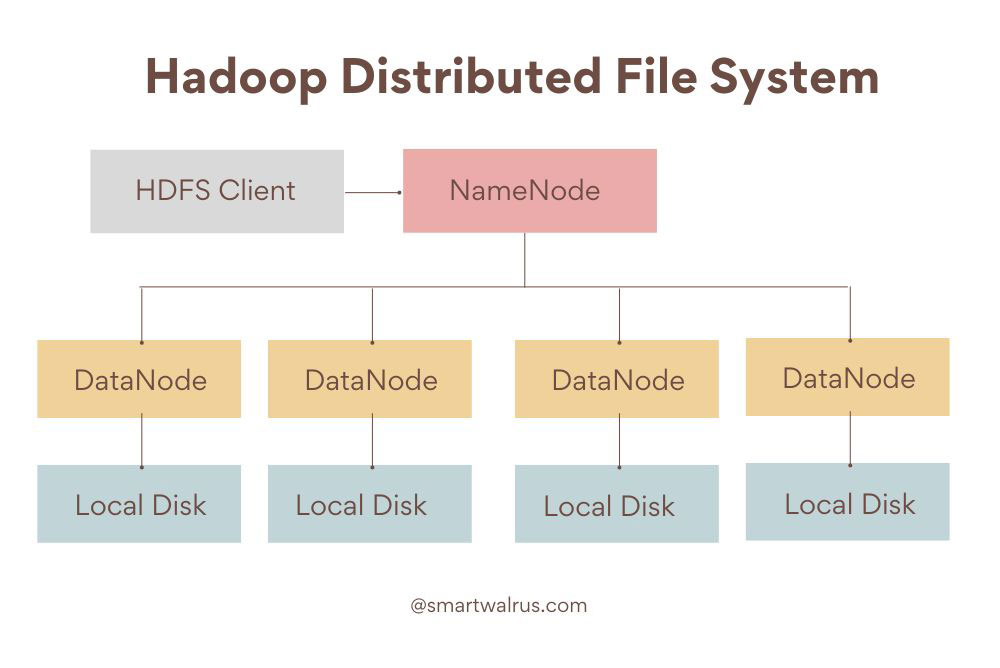
HDFS has a master-slave architecture with a NameNode as the master node that manages the file system metadata and DataNodes as the slave nodes that manage the storage attached to each node. HDFS is designed to support very large files and provide high throughput access to these files.
It also provides a set of APIs for applications written in Java, Python, and C++ to access the data stored in HDFS. HDFS can store large volumes of data from different sources such as log files, images, videos, and audio. It is ideal for storing and processing large datasets for analytics and machine learning.
2. MapReduce Programming Framework
MapReduce works by dividing a large problem into smaller subproblems that can be solved in parallel. The map step processes each piece of data and produces a list of intermediate key-value pairs. The reduce step then aggregates all intermediate values associated with the same intermediate key and produces the final result.
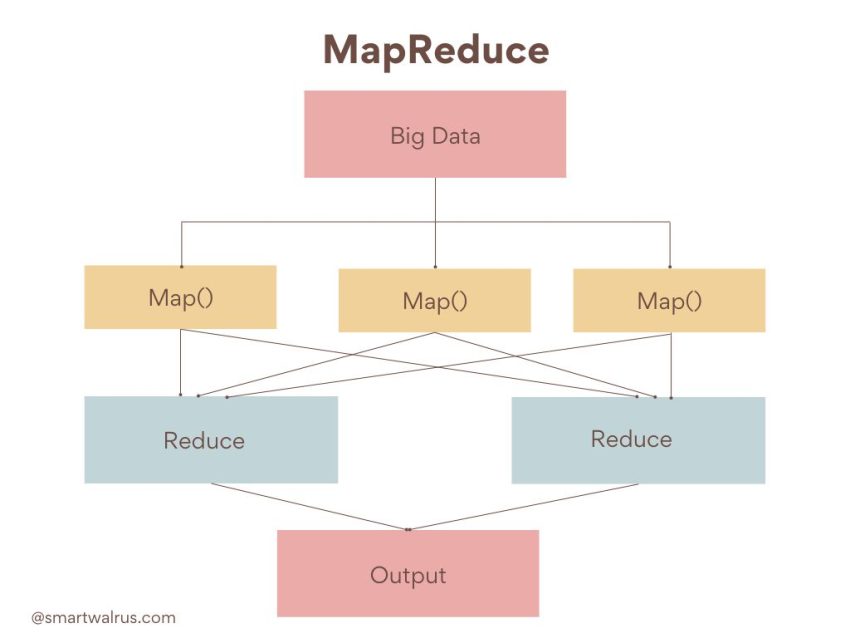
MapReduce is an effective way to process large datasets because it makes use of distributed computing to process data in parallel, which reduces the amount of time required to process the data. It also allows for easy fault tolerance, since if one node fails, the other nodes in the cluster can pick up the slack.
MapReduce has many applications in Big Data such as search engines, web indexing, machine learning, data mining, etc. It has been used successfully in large-scale data analysis projects such as Google’s search engine and Amazon’s recommendation engine.
Apache Hadoop Industry Uses and Applications
Apache Hadoop is used by organizations from different industries to help them store, process, and analyze data quickly and cost-effectively. Some of the industries that use Apache Hadoop include:
- Financial services: Financial institutions use Apache Hadoop to process customer data, analyze customer behavior, and detect fraudulent activities.
- Retail: Companies in the retail industry use Hadoop to manage their customer data, track inventory levels, and optimize supply chains.
- Healthcare: Hospitals and other healthcare organizations use Hadoop to store and analyze medical records, improve patient care, and reduce costs associated with medical records management.
- Telecommunications: Telecom companies use Hadoop to process customer data, analyze call logs, and improve network performance.
- Government: Governments around the world are leveraging Hadoop to process census data, monitor population trends, and implement policies.
- Education: Colleges and universities use Hadoop to store and analyze student data, track enrollment trends, and facilitate data-driven decision-making.
- Media and Entertainment: Media and entertainment companies use Hadoop to store and analyze vast amounts of content, analyze user behavior, and improve customer engagement.
- Manufacturing: Manufacturers use Hadoop to store and analyze product information, track production processes, and streamline supply chain management.
Apache Hadoop is an invaluable tool that many industries leverage to manage, store, and process large amounts of data. It helps organizations gain insights, optimize operations and gain a competitive edge.
How Can Apache Hadoop Help Your Business?
Apache Hadoop can help businesses in a variety of ways, including:
Overall, Apache Hadoop can help businesses save money, gain valuable insights from their data, improve security, and better serve their customers. By embracing this technology, businesses can stay competitive and achieve greater success.
Conclusion
Big data is not just for data scientists anymore! Hadoop is a powerful, open-source framework that can help you manage your data. It can process and analyze massive amounts of data, from petabytes up to exabytes.
Whether you need to store, manage, or process your data, Hadoop may be the right solution for you. With the right tools and training, you can use Hadoop to save money, improve operations, and boost sales.
Find out more about how big data can grow any business and learn how you can stay on top of the curve.
Related Big Data
An Overview of Big Data Careers: Make Big Data Your Career
How Big Data and the Internet of Things (IoT) Are Revolutionizing Industries
How Big Data Can Help Your Business Grow
The Pros and Cons of the Internet of Things (IoT)
The 5 V’s of Big Data
An Introduction to Apache Hadoop: What Is It and How Can It Help Your Business?
13 IoT Uses And Applications for a Connected World
What Is A Data Mining Specialist and What Does It Do?