ETL Explained: What Is Extract, Transform and Load (ETL) Process?
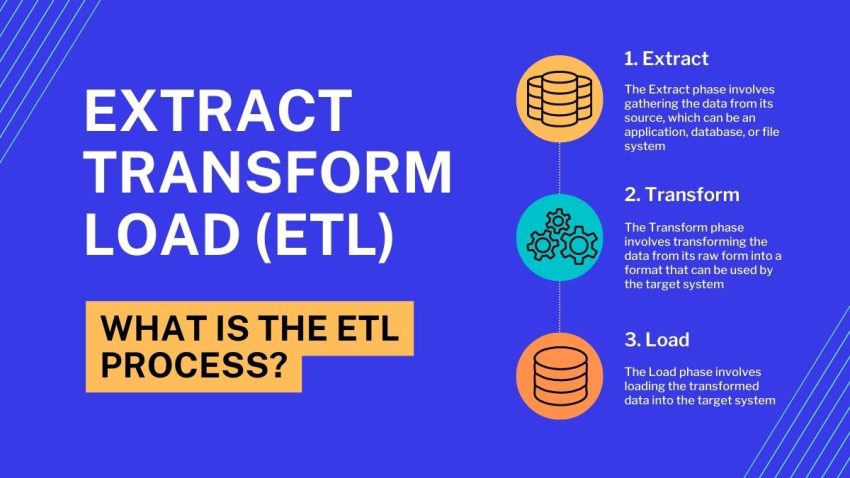
What Is Extract, Transform, and Load (ETL)?
Extract, Transform and Load (ETL) is an important tool in the data engineering space. It is the process of fetching data from one or more data sources, transforming it according to business requirements, and then loading it into a target database.
A data engineer is responsible for streamlining data production by implementing data processing systems with ETL tools. To explain it in a different way, a data engineer’s role is to take raw data and make it usable through different modeling and analytics processes. In this guide, we’ll discuss the basics of ETL and how it works.
What is ETL?
ETL stands for Extract, Transform, and Load. This is a set of techniques in which you can integrate data from a variety of sources and preprocess it for a target destination. The simplest example of this would be loading a table in a relational database. This would include extracting data from a file, applying a formula to it, and then loading it into the database.
ETL is often done with business intelligence tools, data warehouses, and data analytics software. The data engineering role uses ETL processes to move data from one application to another. This could be from a CRM application to a website inventory. It might also move data from one database to another.
ETL is a core concept in data engineering and data management. This is because it solves the problem of integrating data from different systems. Data engineers can also use it to transform data to conform to business requirements. It is an important task in the data engineering process because it allows data to be easily transferred between systems.
")
How Does ETL Work?
As mentioned already, ETL is a process used to move data from one system to another. The process involves extracting the data from its original source, transforming it into a format that can be used by the target system, and then loading it into the target system.
- Extract – First, the Extract phase involves gathering the data from its source, which can be an application, database, or file system. The data is extracted in its raw form and put into a staging area, such as a file data warehouse, file system, or database, where it can be temporarily stored.
- Transform – Secondly, the Transform phase involves transforming the data from its raw form into a format that can be used by the target system. This may involve cleaning or validating the data, as well as applying business rules or calculations.
- Load – Finally, the Load phase involves loading the transformed data into the target system. This phase may also involve indexing the data, creating backups, or running tests to ensure the accuracy of the data.
ETL is an important process for businesses, as it allows them to transfer data between systems quickly and efficiently through data pipelines. It can also help reduce the duplication of data, as the same data does not have to be stored in multiple systems.
The Benefits of ETL
Here are some of the biggest benefits of implementing ETL in an organization:
ETL Tools & Technologies
There are many technologies and tools used for ETL. These tools can transform data from one database or file format to another database or file format. You can typically use them for data warehouses and data analytics environments.
Here are some of the most common ETL tools and technologies available today:
AWS Glue – Amazon Web Services (AWS) Glue is a fully managed, serverless data integration service that makes it easy to prepare and load data for analytics. With AWS Glue, customers can create data models, transform and move data between various data stores, and automate data pipelines to run on a regular schedule
Azure Data Factory – Azure Data Factory is a cloud-based data integration service that allows you to create data-driven workflows for orchestrating and automating data movement and data transformation. With Azure Data Factory, you can create repeatable data-driven workflows so you can trigger on-demand schedules to run automatically.
Google Cloud Data Flow – Google Cloud Dataflow is a managed service for developing and executing a wide range of data processing patterns including ETL, batch computation, and streaming analytics. It allows developers to create data pipelines that ingest data from a variety of sources, process it, and analyze and store the results.
IBM InfoSphere DataStage – IBM InfoSphere DataStage is a powerful ETL tool for integrating large amounts of data from disparate sources. It provides a graphical environment for designing, developing, and executing data integration jobs.
Oracle Data Integrator – Oracle Data Integrator (ODI) is an ELT data integration platform developed by Oracle Corporation. It enables businesses to efficiently manage their data integration processes, including loading data into target systems and transforming data as part of the process.
Examples of ETL
Here are some examples of ETL and common use cases for it:
Best Practices for ETL
Before you set up an ETL process, here’s what you consider part of that data pipeline workflow:
Conclusion
ETL (Extract, Transform, Load) processing is an important tool for data engineers. It helps businesses to gather data from multiple sources, transform it into a usable format, and then load it into a data warehouse or other system for analysis and reporting.
ETL processing can help businesses to create more accurate and timely reports, provide better customer insights, improve operational efficiency, and gain a competitive advantage in the market. It is also an essential tool for integrating data from multiple sources, allowing businesses to make better decisions based on an understanding of their data.
By automating the extraction, transformation, and loading processes, businesses can save time, money, and resources while also ensuring data accuracy and consistency. Overall, ETL processing is an important tool for businesses that need to manage large amounts of data and use it to make informed decisions.
Related Data Engineering
An Introduction to Data Engineering: The What, Why and How
Demystifying the Data Science Roles
The Basics of Data Pipelines: What You Need to Know
How I Became a Data Engineer: A Guide To The Journey
ETL Explained: What Is Extract, Transform and Load (ETL) Process?
The Dark Side of Data Engineering: 19 Things To Hate
How To Become A Data Architect: Skills and Responsibilities
The Data Engineering Toolkit: What Tools Do Data Engineers Use?